计算机原理
2016-02-17 23:57:06CPU是什么
我们都知道的定义是这样的:CPU又称中央处理器,它的英文全称为:Central Processing Unit,但同时如果你听到:Central Processor或者Main Processor往往同样也指的是CPU。
普通程序员开发的程序,其实绝大多数指的就是对中央处理器也就是CPU的编程。这句话也可能会被面试人员反着描述为,计算机的可编程性主要是指对中央处理器的编程。
在最初的时候,大约是1970年代以前,中央处理器由多个独立单元构成,后来才发展成集成电路,这些高度收缩的组件就是所谓的:微处理器。
另外,中央处理器广义上来说,是可以指代一系列可以执行复杂的计算机程序的逻辑机器。还记得三体中秦始皇嬴政派出无数士兵进行逻辑与或非运算吗?那样的场景,其实就是实现了广义上的中央处理器。
注意:ENIAC(Electronic Numerical Integrator And Computer)是世界上第一台”电子存储式可编程计算机”,但是由于他们也存在计算功能,而CPU的标准定义为:执行软件(计算机程序)的设备所以,ENIAC理论上不存在标准的CPU,但是最早于存储程序型计算机一通登场的设备是可以被称作CPU的,也就是说:CPU并不一定是微型的,早起的同步CPU是非常大的。直到1950~60年代的晶体管CPU时,CPU才慢慢变小。不再以体积庞大,不可靠与易碎的开关组件(继电器/真空管)组成或建造。
参考来自于维基百科,与哈佛计算机原理书籍,国内的一些小众参考资料与翻译是错误的,一定要注意。CPU并不小。尤其是百度百科,它所提供的参考资料只提及了”微”,但是万物相对论,没有相对何来形容词?从本段落开始,咱们只讨论:冯·诺依曼机,不讨论哈佛架构。
CPU的主要运作原理
CPU的主要运作原理很简单。不论其外观,都是执行存储与被称为”程序”里的一系列指令。所以说计算机是最愚蠢的傻子,没有码农他们就是一坨铁。
在冯诺依曼架构中,程序以一系列数字存储在计算机存储器中。
而只要是冯诺依曼机,CPU的运作原理就可以看成四个阶段:提取,解码,执行,回写。
- 提取:从程序内存中检索指令(程序内存,指的可不是你程序里面定义了一个int的这个内存,而是存储程序的内存),由程序计数器指定程序存储器的位置,计数器保存供识别当前程序位置的数值(原始资料原文)。 拿人话说:程序计数器记录了CPU在当前程序里的踪迹(你跑哪去了?)提取指令后,根据指令式等内容的长度增加存储器单元。指令的提取常常必须从相对较慢的存储器查找,导致CPU等候指令的送入。(关键问题是:CPU指着整个计算机存储体系温柔的说道,我不是指你啦外存,我是说在坐的各位,都是垃圾) 上面是理工科的话,再拿麻瓜的话来说: 程序计数器其实非常傻,他记录的是内存的地址,而不是指令。这时候就尴尬了,他的增长取决于指令在内存中所占的单位数,在固定长度的指令ISA(微处理器的指令集架构Instruction Set Architecture)中,每个指令所占用的内存单位是相同的(简单说就是它傻到只能某几个某几个数,而不能一个一个数)。例如:32位的ISA固定长度指令使用8位内存单位。而且每次将增加4个PC单位,也就是32Bit。而类似于现在咱们大家常用的X86,虽然也是默认指代32位,然而这之间有一些区别。X86的CPU其实是可以处理16位与8位的,他的PC在内存中的增长量取决于最后一个指令的长度。而更复杂的的CPU中,最后一个指令的运行不一定会导致PC单位的增长,特别是大量数据传输和超标量体系结构中。 所以如果要讨论指令集,那么你必须讨论清楚所有的细节,否则,你们没人说错,但是永远对不了。 上面说了一堆的CPU提取动作,下来来看看后面几个顺理成章的事情。
- 解码:CPU从存储器提取到指令,他需要被解码才能成为有意义的片段,根据不同CPU的指令集会变成对应的指令。一部分为运算码,其他的是必要信息。或者是寄存器/存储器地址,以地址模式决定。 MSIL就是微软的汇编语言。看到上面这段,是不是特别的熟悉呢?
- 执行:执行是最容易理解的地方,根据不同的指令与对应的其他信息,来进行简单的运算与逻辑运算,例如加法/位操作。 其实CPU有多愚蠢呢?他也就只会:与或非异或。是的他就是如此的愚蠢。
- 回写:则更容易理解,由于CPU是专门负责计算的,总不能算完了还放在CPU里面?那不行。所以,它会先回写/写回到缓冲区,然后同步给主存,然后就没然后了,程序该干啥干啥。
为什么会出现不同的系统不兼容的情况
根据上面CPU的工作原理,其实非常容易看出来一个事情。
那就是:指令集问题怎么办?你能看到英特尔与AMD还能兼容,那是因为他们都是X86架构体系的。
如果你把他们对比成:X86与ARM,那就好玩了。
甚至于说X86与X64有时候都不兼容。
如果你工作足够早,你应该听说过X86跟X64是完全不能跑的,但是后面似乎成了32位的能在64下跑,而64不能在32上跑。而这个事情其实只有一个原因:X64原始名字应该是X86-64,也就是X86指令集的64位扩展。
而系统级别的不兼容其实更容易理解。
由于每一个系统的API都是不同的,普通开发编写的程序都是在Kernal之上的,那么与其说你是面向CPU,倒不如说是面向系统的API编程,那么LINUX与windows的API一日不相同,则永远不可能出现完全兼容。
甚至每个系统的策略也不同,例如WIN7开始不允许进行MAC层编程,而LINUX可以,这也就是为什么工控软件为什么不会出现windows 的原因。。我没有IP,你还不允许我使用MAC层编程,怎么着?让我们集体跳楼嘛?
存储体系的几大模块
有些人说:存储体系分为4个,有些人说分为6个,有些人说3个。
其实大家都对,只是大家的理解方式不同。
完整的完全体是6个。如下:
- A1:寄存器(32位处理器的话每个寄存器是32位X86架构下有16个寄存器)
- B2:第一级高速缓存
- B3:第二级高速缓存
- B4:第三级高速缓存
- C5:主存
- D6:外存
4个的人认定的是大写英文字母版本,也就是寄存器,高速缓存,主存,外存。
6个的人认定是完全版,也就是数字版本。
而3个的人说的是能够使用软件去想办法利用的资源比较偏向于软件。
注意:软件不是不能利用寄存器,只是正常情况下尤其是类似编写NET或JAVA等高级语言的人员,是没有意义的。
存储体系在设计系统与开发系统时的重要性
CPU说:不不不,我不是说外存你,我是说,在座的各位,都是垃圾。
其实这句话的含义你仔细理解一下,它完全代表了软件的架构模式,而且是100%匹配。
你的For循环或者任何一段运算速度是绝对快于内存的访问速度的,例如redis的存储与获取。
这时候你如果不想让Redis崩溃掉,你唯一的选择是什么?对的,你给本地加缓存
这个场景其实与CPU和主存之间的工作模式是完全一致的。
由于主存与CPU之间的性能差异,又不可能说让CPU去等待主存将内容完全读取走,这才出来了1234级缓冲,而如果你对硬件稍微熟悉的话,你会发现,每一层缓冲区数量普通情况下是越来越大的。
同样的情况,你来合计一下,这次是主存与外存了,那么对标软件中的哪个位置呢?
你在开发软件的时候或者设计架构的时候什么时候其实就是硬件架构的软件实现呢?
缓存Cahce,缓冲Buffer你能分清两者的区别嘛
大家伙经常说:所谓概念就是概念,没啥用。我背过就好。
那你应该如何去阐释,作业本长一样,习题内容一样。考的试一样,老师一样,时间一样精确到皮秒。但你跟你班上的学霸,是如何出现越来越大的差异的?
这就是,你跟你的学霸朋友,谁是缓存了,谁是缓冲了的问题。
从存储可靠度来说,这两者都不可靠,你在设计软件时,不能认为缓存是可靠的,更不能认为缓冲是可靠的。
但是如果非要在这两者之间选择:相比较于缓冲,你更需要的是缓存。
例如刚才的例子:学霸是缓存下来,回去消化,而你是缓冲下来,下课就倒掉了。这是个很尴尬的场景。
仔细斟酌我的例子,你能发现有什么可落地的场景嘛?
注意一个细节:缓存是不可复用的,而缓冲是必须复用的。对了,做UI的人肯定听说过一个叫做双重缓冲的技术。这个又是什么鬼?
来,咱们一起落地这个概念吧!在实际的项目中,缓存与缓冲是怎么使用的
- 视频处理项目的缓冲与缓存。
- 在线直播项目的缓冲与缓存
- 2B项目的缓冲与缓存
- 金融项目的缓冲与缓存
- 引擎类项目的缓冲与缓存
- 通信项目的缓冲与缓存
网络模型
网络模型,是最好玩的一个,人话与鬼话混合的内容。简单来说,网络模型一般都是指代标准的OSI7层模型
| OSI | TCP/IP |
|---|---|
| 应用层 | 应用层 |
| 表示层 | |
| 会话层 | |
| 传输层 | 传输层 |
| 网络层 | 互联层 |
| 数据链路层 | 链路层 |
| 物理层 |
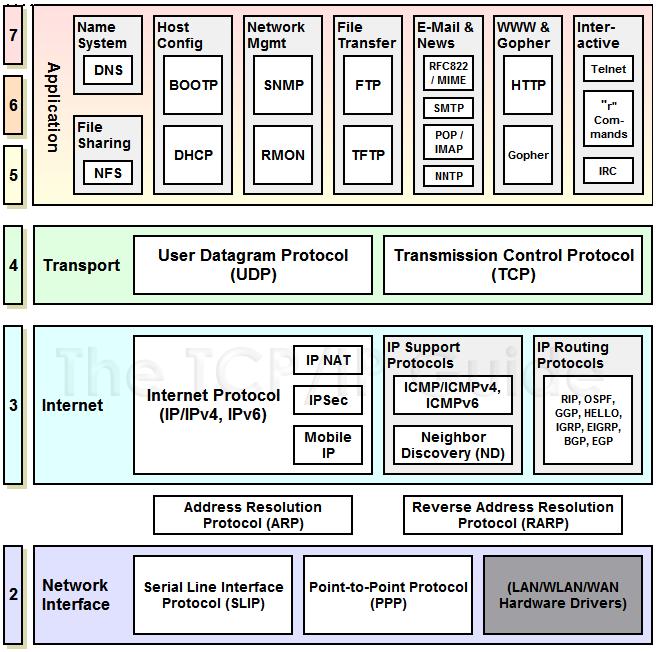
Socket是什么
Socket光在计算机专业,就能代指好几个内容。
- 网络通信的socket
- Unix Domain Socket。
- CPU Socket,指的是主板与CPU连接的那一堆东西(对你没想错)
好玩的是:Socket最初是加利福尼亚大学伯克利分校给Unix开发的网络通信接口(与上面的第2个不同),后来随着TCP/IP的发展,诶~就成了通用的标准接口了。所以Windows也支持。
而且,微软最开始有自己的windows socket,只支持TCP/IP协议,后面的才更新的新的,所以在linux与windows 下开发原始套接字的时候创建方式都有变化。例如CPP可绑定的参数是不一样多的。
由于套接字是有一定统一性的,根据接口不变原则。
绝大多数的套接字过程无非如下:
侦听方:bind->Listen->AcceptClient->ReceviceData->DoWhat you want->Send
连接方: Connect->send->ReceiviceData
网卡
CPU跑的最欢,下来是主存,然后是外存。那么网卡是外接器件,算输入输出类型的内容。而且造价也低。按照这个概念。网卡的速度,应该。。不快?
非常容易推理的一个事情就是。
如果某一个请求需要经过网卡。
那么它就可以说是属于IO操作了。
根据CPU与IO之间的运行原理,我需要”异步”它。
CDN
CDN全称:Content Delivery Network或Content Ddistribute Network,即内容分发网络。
CDN设计思路
- 避让:尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。
- 检测:通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,CDN系统能够实时监测网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求。
- 分发:根据监测情况重新导向离用户最近的服务节点上。
12306使用CDN加速的例子:用户下订单拿到token---》服务器通过消息队列把token推到CND---》用户去CDN查询订单结果(减轻服务器压力)
可运维性
可能很多人都知道可维护性。
有人清楚”可运维性”是什么意思嘛?
当然,这个词貌似是生造的,但是表达的意思非常好。
也能体现架构师的一个非常重要的作用。
架构师值钱,并不是值钱在所谓的设计良好的软件,能够XXX,其实这些内容理论上SSE即可完成。而架构师值钱的点还有一个很重要的地方:”可运维性”。
简单来说,至少有下面这些内容需要满足:
- 兼容性,包括但不限于:接口,函数,参数,返回值
- 性能报告:多久会崩溃,人数到达多少会崩溃,流量峰值到达多少会死,击穿条件,边界。
- 数据节点跳转个数:也就是一条数据从收到到最后返回结果总共跳转了多少次。
- 故障隔离与降级:并且提供隔离后不会造成雪崩的情况。
- 访问策略控制
- 异步&同步控制:不同的状态分布在不同的节点上,做不同的事情与倾向点。
什么是线程
线程(英语:thread)是操作系统能够进行运算调度的最小单位。大部分情况下,它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在Unix System V及SunOS中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程。 线程是独立调度和分派的基本单位。线程可以为操作系统内核调度的内核线程,如Win32线程;由用户进程自行调度的用户线程,如Linux平台的POSIX Thread;或者由内核与用户进程,如Windows的线程,进行混合调度。
线程有4个状态
- 产生(spawn)
- 中断(block)
- 非中断(unblock)
- 结束(finish)
不同的平台,线程的理解也不尽相同。
比如:
unix有International线程。
SUN Solaris操作系统使用的线程叫做UNIX International线程,支持内核线程、轻权进程和用户线程。一个进程可有大量用户线程;大量用户线程复用少量的轻权进程,轻权进程与内核线程一一对应。用户级线程在调用核心服务时(如文件读写),需要“捆绑(bound)”在一个LWP上。永久捆绑(一个LWP固定被一个用户级线程占用,该LWP移到LWP池之外)和临时捆绑(从LWP池中临时分配一个未被占用的LWP)。在调用系统服务时,如果所有LWP已被其他用户级线程所占用(捆绑),则该线程阻塞直到有可用的LWP。如果LWP执行系统线程时阻塞(如read()调用),则当前捆绑在LWP上的用户级线程也阻塞。
如果是它的话头文件是Thread.h
还有一个叫做POSIX的线程
POSIX线程(POSIX threads),简称Pthreads,是线程的POSIX标准。该标准定义了创建和操纵线程的一整套API。在类Unix操作系统(Unix、Linux、Mac OS X等)中,都使用Pthreads作为操作系统的线程。Windows操作系统也有其移植版pthreads-win32。
如果是POSIX的话,头文件是pThread.H
而windows就比较简单了,只有一个Win32线程,包含:寄存器,核心栈,线程环境块与用户栈。
CPU如何理解线程
线程是CPU的实际调度和分派的基本单位,比如说你写的.net程序。每一个进程至少得有一个线程。这个是必须。
而硬件呢?假设我只有一个核。
那也有:叫做超线程技术的多线程。
比如:我计算偶数的命令是一个,计算奇数的命令是另外一个,利用一些命令模式来拆分指令集或者一些其他的方式来区分运作的内容,达到类似多线程的目的,这叫做超线程,是硬件的多线程技术。
所以:就算是一个核也有多线程,但是并不是完全并行的,因为时间尺度上,它真的做不到了。
请看下面几行文字
- 单CPU中的进程只能并发,多CPU的才能并行。
- 单核中线程只能并发,多核才能并行
那么,你好奇了,第一点我没提及啊。
好的,咱们来补充一下这个内容:
进程:
进程这东西非常神奇,如果程序不控制,它可以把CPU跑到断电。由于有操作系统调度器的关系,进程被弱化到了调度单位。进程好玩的点在于它是N多资源的集合,例如各种外设。
实际上,CPU在同一时刻(物理上的,牛爵爷说的),按照标准的描述来说: A common form of multitasking is time-sharing。 Time-sharing is a method to allow high responsiveness for interactive user applications。 In time-sharing systems, context switches are performed rapidly, which makes it seem like multiple processes are being executed simultaneously on the same processor。 This seeming execution of multiple processes simultaneously is called concurrency。
汉语: 现代计算机系统可在同一段时间内以进程的形式将多个程序加载到存储器中,并借由时间共享(或称时分复用),以在一个处理器上表现出同时(平行性)运行的感觉。同样的,使用多线程技术(多线程即每一个线程都代表一个进程内的一个独立执行上下文)的操作系统或计算机体系结构,同样程序的平行线程,可在多CPU主机或网络上真正同时运行(在不同的CPU上)。
为什么英特尔存在4核8线程
超线程(HT, Hyper-Threading)[1]是英特尔研发的一种技术,于2002年发布。超线程技术原先只应用于Xeon 处理器中,当时称为“Super-Threading”。之后陆续应用在Pentium 4 HT中。早期代号为Jackson。 通过此技术,英特尔实现在一个实体CPU中,提供两个逻辑线程。之后的Pentium D纵使不支持超线程技术,但就集成了两个实体核心,所以仍会见到两个线程。超线程的未来发展,是提升处理器的逻辑线程。英特尔于2016年发布的Core i7-6950X便是将10核心的处理器,加上超线程技术,使之成为20个逻辑线程的产品。 英特尔表示,超线程技术让Pentium 4 HT处理器增加5%的裸晶面积,就可以换来15%~30%的性能提升。但实际上,在某些程序或未对多线程编译的程序而言,超线程反而会降低性能。除此之外,超线程技术亦要操作系统的配合,普通支持多处理器技术的系统亦未必能充分发挥该技术。例如Windows 2000,英特尔并不鼓励用户在此系统中利用超线程。原先不支持多核心的Windows XP Home Edition却支持超线程技术。
程序里头线程是怎么体现的
咱们来看一个老生常谈的问题吧。
控制CPU。
public static class ThreadCore
{
[DllImport("kernel32.dll")]
static extern uint GetTickCount();
//SetThreadAffinityMask 指定hThread 运行在 核心 dwThreadAffinityMask
[DllImport("kernel32.dll")]
static extern UIntPtr SetThreadAffinityMask(IntPtr hThread,
UIntPtr dwThreadAffinityMask);
//得到当前线程的handler
[DllImport("kernel32.dll")]
static extern IntPtr GetCurrentThread();
public static void Init()
{
Thread t1 = new Thread(new ParameterizedThreadStart(Sin));
Console.Write("Which core you will to use (Start from 0):");
string core = Console.ReadLine();
int coreNumber = 0;
try
{
coreNumber = Int32.Parse(core);
}
catch
{
coreNumber = 0;
}
t1.Start(coreNumber);
Console.ReadLine();
}
//休息一半转一半
public static void HalfOfHundred(object coreNumber)
{
int core = 0;
try
{
core = (int)coreNumber;
}
catch
{
core = 0;
}
SetThreadAffinityMask(GetCurrentThread(), new UIntPtr(SetCpuID(core)));
int busyTime = 10;//忙碌周期 Windows的调度周期为10MS左右
int idleTime = busyTime;//沉睡周期
Int64 startTime = 0;
while (true)
{
startTime = System.Environment.TickCount;//当前的时钟周期
while ((System.Environment.TickCount - startTime) <= busyTime)///计算我应该睡多久
{
//这里的空转基本上 就能转到等待的时间直到现在,然后再等对应的时间然后再休息.
//也就是休息一半转一半
}
System.Threading.Thread.Sleep(idleTime);//缓冲一下让CPU休息休息
}
}
//Sin曲线
public static void Sin(object coreNumber)
{
int core = 0;
try
{
core = (int)coreNumber;
}
catch
{
core = 0;
}
SetThreadAffinityMask(GetCurrentThread(), new UIntPtr(SetCpuID(core)));
double split = 0.01;
int count = 200;
double pi = 3.1415962525;
int total_amplitude = 300;
int[] busySpan = new int[count];//来存储每一个周期的忙的时间
//计算在每个Y点上的忙碌的CPU碎片数量
int amplitude = total_amplitude / 2;
double radian = 0.0;
for (int i = 0; i < count; i++)
{
busySpan[i] = (int)(amplitude + amplitude * Math.Sin(pi * radian));
radian += split;
}
uint startTime = 0;
int j = 0;
while (true)
{
j = j % count;
startTime = GetTickCount();
while ((GetTickCount() - startTime) <= busySpan[j])
{
}
Thread.Sleep(total_amplitude - busySpan[j]);
j++;
}
}
//函数中的参数 dwThreadAffinityMask 为无符号长整型,用位标识那个核心
//比如:为简洁使用四位表示
//0x0001表示核心1,
//0x0010表示核心2,
//0x0100表示核心3,
//0x1000表示核心4
public static ulong SetCpuID(int id)
{
ulong cpuid = 0;
if (id < 0 || id >= System.Environment.ProcessorCount)
{
id = 0;
}
cpuid |= 1UL << id;
return cpuid;
}
}
public class Program
{
static void Main(string[] args)
{
ThreadCore.Init();
Console.ReadLine();
}
}

