MongoDB知识点总结
2022-04-02 21:34:55一、MongoDB核心概念
1. 定位与优势
目标:处理海量数据(名称源自"humongous"),支持高可用、水平扩展。
数据模型:
- JSON文档结构:天然贴合面向对象思想,支持嵌套对象和数组。
- 动态模式:使用BSON(JSON的二进制扩展)存储,支持日期、二进制等扩展类型。
核心优势:
- 易用性:类JSON语法降低学习成本。
- 高性能:内存映射引擎、写优化设计。
- 高可靠性:副本集自动故障转移。
- 高扩展性:原生分布式架构(分片集群)。
2. SQL vs MongoDB概念对比
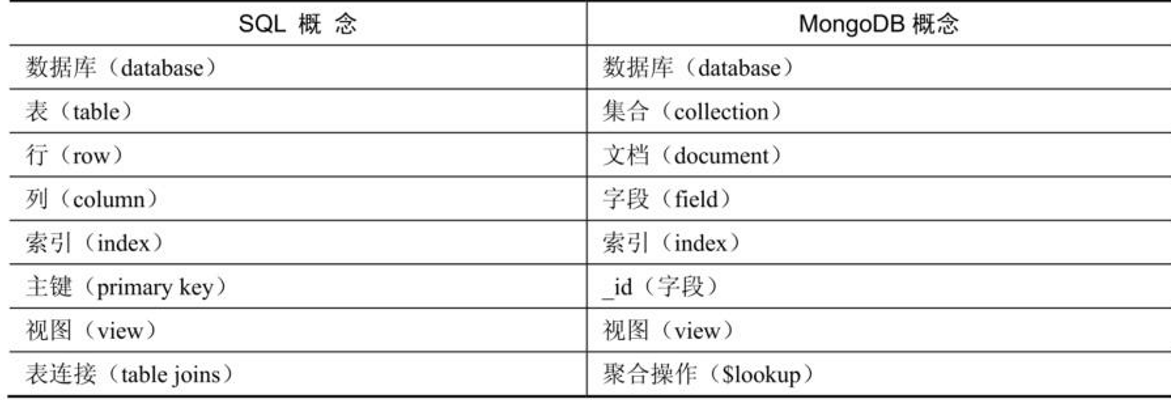
关键差异:MongoDB属于半结构化数据模型,无固定表结构,不支持事务级JOIN。
二、基础操作实战
1. 集合与文档操作
// 创建/切换数据库
use sample
// 插入文档
db.persons.insertOne({ name: "张三", age: 22 })
db.persons.insertMany([...])
// 查询文档
db.movies.find( { "year" : 1975 } ) //单条件查询
db.movies.find( { "year" : 1989, "title" : "Batman" } ) //多条件and查询
db.movies.find( { $and : [ {"title" : "Batman"}, { "category" : "action" }] } ) // and的另一种形式
db.movies.find( { $or: [{"year" : 1989}, {"title" : "Batman"}] } ) //多条件or查询
db.movies.find( { "title" : /^B/} ) //按正则表达式查找
// 更新与删除
db.persons.updateMany({ age: 22 }, { $set: { status: "active" }})
db.persons.deleteMany({ age: { $lt: 18 }})
db.runCommand({ drop: "persons" }) // 删除集合
2. 查询条件对照表
| SQL | MQL |
|---|---|
| a = 1 | { a: 1 } |
| a <> 1 | { a: { $ne: 1 } } |
| a > 1 | { a: { $gt: 1 } } |
| a >= 1 | { a: { $gte: 1 } } |
| a < 1 | { a: { $lt: 1 } } |
| a <= 1 | { a: { $lte: 1 } } |
3. 查询逻辑对照表
| SQL | MQL |
|---|---|
| a = 1 AND b = 1 | {a: 1, b:1 } 或 { $and: [ {a: 1}, {b: 1}] } |
| a = 1 OR b = 1 | { $or: [ {a: 1}, {b: 1}] } |
| a IS NULL | { a: { $exists: false } } |
| a IN (1, 2, 3) | { a: { $in: [1, 2, 3 ] } } |
4. 查询逻辑运算符
$lt: 存在并小于
$lte: 存在并小于等于
$gt: 存在并大于
$gte: 存在并大于等于
$ne: 不存在或存在但不等于
$in: 存在并在指定数组中
$nin: 不存在或不在指定数组中
$or: 匹配两个或多个条件中的一个
$and: 匹配全部条件
5. 数据结构特色
原生支持复杂类型:数组和嵌套对象作为"第一公民",无需序列化。
{ name: "李四", tags: ["工程师", "后端"], address: { city: "北京", zip: "100000" } }对比传统方案:
- 平铺多列(如
tag1,tag2) → 扩展性差。 - 序列化为字符串 → 读写需额外解析。
- 平铺多列(如
6. ObjectId
objectid是12字节的二进制数据,使用16进制编码的字符串形式
- 前4字节,当前时间的Unix时间戳,精确到秒
- 中5个字节,随机数,机器标识符和进程ID的哈希值
- 后3个字节,自增到计数器,初始值随机
7. 固定集合(Capped Collection)
用途:存储日志、传感器数据等临时态数据。
特性:
- 固定大小,写满后自动覆盖旧数据(FIFO)。
- 高性能顺序读写,适用于流式数据。
// 创建固定集合(最大10条文档,总大小4096字节) db.createCollection("logs", { capped: true, size: 4096, max: 10 })
三、高级查询与优化
1. 聚合管道(Aggregation Pipeline)
原理:数据流经多个处理阶段(类似流水线),最终输出结果。
常用阶段运算符:
阶段 作用 SQL等价运算符 $match过滤 WHERE $group分组 GROUP BY $sort排序 ORDER BY $skip/$limit分页 SKIP/LIMIT $unwind展开数组字段 $project投影 SELECT $lookup 左外连接 LEFT OUTER JOIN 示例:统计各城市用户平均年龄
db.persons.aggregate([ { $group: { _id: "$address.city", avgAge: { $avg: "$age" } } } ])
2. MongoDB 索引的特色(与传统目录的不同):
- 多层目录(多字段索引/复合索引):
- 传统目录:可能只能按书名或者作者名一种方式排。
- MongoDB:可以按多个字段建索引,就像
{ lastname: 1, firstname: 1 },先按姓排,姓相同再按名排(对find({lastname: "张", firstname: "三"})非常高效)。📚
- 给书里的小纸条做目录(嵌套字段索引):
- 传统目录:只能索引整本书的主要标题。
- MongoDB:如果文档里有嵌套对象(如
address: { city: "北京", street: "中关村" }),你可以直接给address.city建索引,像db.users.createIndex({ "address.city": 1 })。
- 给书本列表做目录(数组索引):
- 传统目录:很难索引书里提到的所有名词列表。
- MongoDB:如果一个字段的值是个数组(如
tags: ["科技", "编程", "数据库"]),你可以创建索引db.articles.createIndex({ tags: 1 })。查询find({ tags: "编程" })就能用到这个索引来快速找到包含“编程”标签的文章。这是 MongoDB 特有的强大功能。
- 更强大的目录结构(多种索引类型): 除了最常见的 B-Tree(高效范围查询和等值查询),MongoDB 还支持其他类型:
- 文本索引(Text Index): 专门用于在文档中搜索单词或短语(全文搜索)。
- 地理空间索引(Geospatial Index): 用于高效查询位置(经纬度)数据(比如查找附近的咖啡店)。
- 哈希索引(Hashed Index): 用于快速等值查询,但不支持范围查询(
>,<这种不行)。 - 唯一索引(Unique Index): 确保某个字段的值在整个集合中是唯一的(比如
email)。 - TTL 索引(TTL Index): 让文档在指定时间后自动过期删除(比如存储会话或日志数据)。
3. 与传统数据库(如 MySQL)索引的对比
| 特点 | MongoDB 索引 | 传统关系型数据库 (RDBMS) 索引 |
|---|---|---|
| 基础结构 | 通常是 B-Tree,但也支持多种其他类型 (Hash, Geospatial, Text 等)。 | 几乎总是 B-Tree 或 B+Tree(最主流)。 |
| 索引对象 | JSON 文档的字段或路径 (包括顶层字段、嵌套对象字段 obj.field)。 |
表里的列 (Column)。 |
| 处理灵活性 | 文档结构可以动态变化,索引创建相对灵活(可以在已有数据上直接创建)。 | 表结构相对固定(Schema),索引创建通常在严格模式约束下进行。 |
| 数组索引 | ⭐ 支持!可以索引数组字段或数组中的元素(tags: [“a”, “b”] 上索引,查询 {tags: “a”} 可用索引)。 |
❌ 不支持直接索引“数组”列本身(通常需要关联表/JSON函数支持,较复杂)。 |
| 复合索引 | ✅ 支持多个字段组合 ({field1: 1, field2: 1})。 |
✅ 支持多个列组合 ((col1, col2))。 |
| 覆盖查询 | ✅ 支持。查询只需要索引包含的字段时,可以只读索引,更快。 | ✅ 同样支持。使用覆盖索引 (Covering Index) 避免查表。 |
| 管理/维护 | 语法略有不同 (createIndex()),后台异步构建。占用存储空间,增删改操作需维护索引(影响写性能)。 |
语法不同 (CREATE INDEX ...),可能阻塞或后台构建。占用存储空间,增删改需维护索引(影响写性能)。 |
| 核心目的 | ⚡ 提升查询速度!减少全集合扫描。 | ⚡ 提升查询速度!减少全表扫描。 |
| 核心原理 | 通过创建额外的、有序的数据结构(通常是 B-Tree),映射字段值到文档位置。 | 通过创建额外的、有序的数据结构(通常是 B-Tree 或 B+Tree),映射字段值到行位置(ROWID/主键等) |
4. 关键相似点
- 核心作用一样: 都是为了加速查询!避免慢吞吞的全集合/全表扫描。
- 原理类似: 都是创建一个高效的、通常是排序的(如B-Tree)数据结构,将键值映射到数据所在位置。
- 有代价: 写数据(增、删、改)时需要额外维护索引,占用磁盘空间。不是越多越好,需按需创建。
- 查询优化器决定用哪个: MongoDB和RDBMS都有优化器,它会尝试选择最合适的索引来用(你可以用
explain()看看它选的对不对)。
四、高可用架构:副本集(Replica Set)
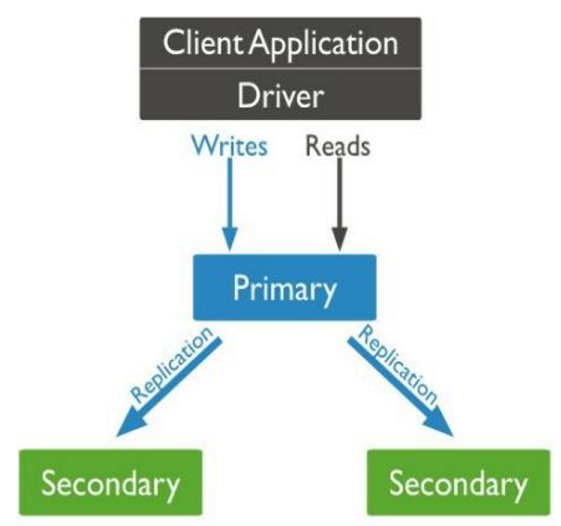
1. 核心架构
组成:1个主节点(Primary) + N个备节点(Secondary)。
MongoDB副本集是什么
- 类似一个 数据库小团队(通常3个以上成员)
- 包含三种角色:
- 主节点:唯一可读写的数据库(老板)
- 从节点:数据备份+只读(员工)
- 仲裁节点:只投票不存数据(裁判)
什么时候会触发选举
- 主节点宕机(服务器停电/崩溃)
- 主节点网络断开(掉线超过10秒)
- 手动维护(管理员强制切换)
- 超过半数节点失联(团队分裂)
注意:选举需要大多数节点存活(3节点至少2个在线)
故障转移流程:
- 主节点故障 → 备节点检测并发起选举。
- 基于Raft算法选举新主节点(多数投票机制)。
- 客户端自动重连新主节点。
2. Raft算法核心原理(会选举版)
类比 团队选新领导 的流程:
- 角色三种状态
| 状态 | 作用 | 类比 |
|---|---|---|
| Leader | 主节点,处理所有写请求 | 团队领导 |
| Follower | 从节点,同步数据 | 普通成员 |
| Candidate | 选举中的临时状态 | 竞选人 |
选举四步走
- 等待超时:当一个Follower节点(比如节点A)长时间没收到Leader的心跳(超过150~300ms的随机时间),它就开始觉得Leader可能挂了,于是自己发起选举。
- 发起投票:节点A先给自己增加一个任期号(比如之前的任期是1,现在变成2),然后向所有其他节点发送投票请求:“我要竞选新Leader,这是新任期2,请支持我!”
- 投票表决:其他节点收到请求后,在同一个任期内,它们只能投一次票,并且通常会给第一个符合条件的请求投票。节点A等待投票结果。
- 结果处理:
- 如果节点A得到了超过半数节点的投票(比如3节点集群需要2票),它就成功升级为Leader。
- 如果没有得到足够的票数(比如只有1票),节点A就会放弃竞选,重新变回Follower。
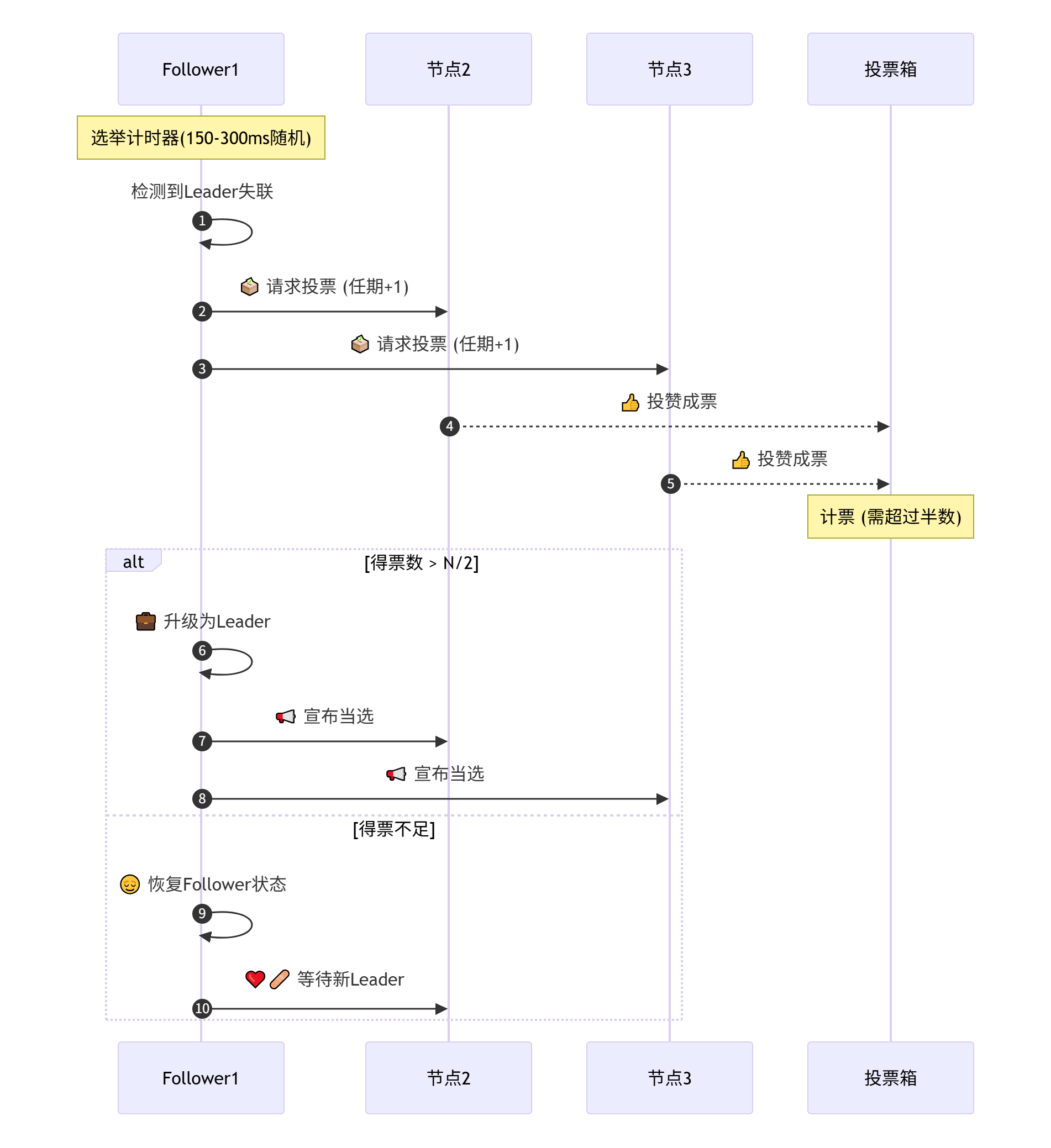
关键规则
- 随机超时:每个节点等待时间不同,避免同时竞选
- 任期(term)递增:每次选举用更大的编号(像会议届数)
- 多数票原则:必须获得 (N/2)+1 票(3节点需2票)
- 日志匹配:新主节点必须有最新数据(保证数据不丢失)
为什么需要Raft?
问题 Raft的解法 脑裂(多个主节点) 多数票制,只允许一个主 数据丢失 只让最新数据的节点当选 无限选举僵局 随机超时打破平票 💡 总结:副本集像带自动选举的数据库团队,Raft是确保快速安全换领导的投票规则!
3. 数据实时复制原理
Oplog(Operation Log操作日志):
- 主节点记录所有写操作的固定集合(Capped Collection)。
- 备节点异步拉取Oplog并重放操作。
- 如果差异太大(如从节点落后几小时),会触发全量同步
复制延迟优化:
- 扩容Oplog(默认占用磁盘5%空间)以容忍更高延迟。
实时复制流程
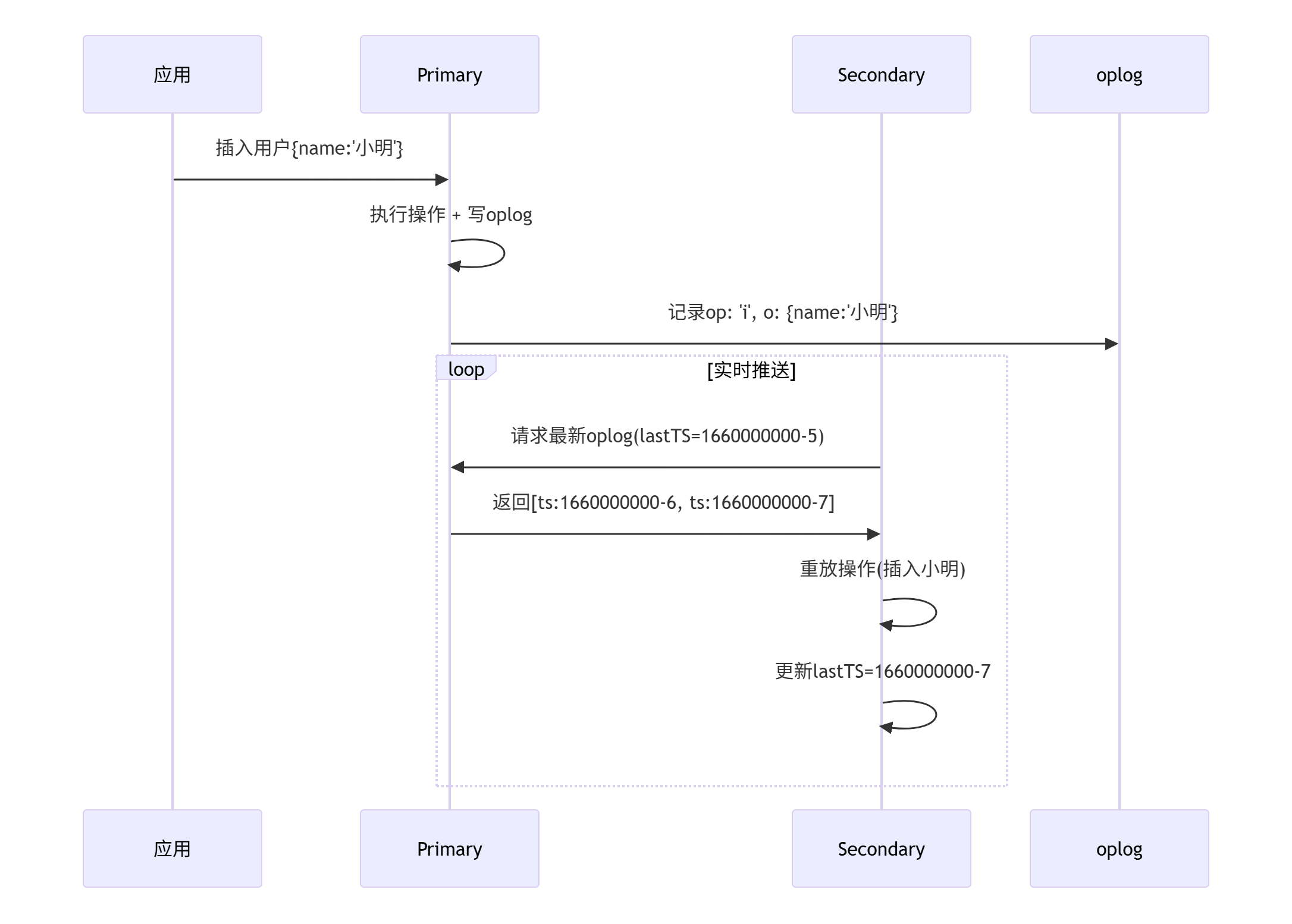
关键步骤解析:
从节点主动拉取 每个从节点有自己的"阅读进度条"(
lastTS),每隔100ms左右问主节点:"有没有日志?"主节点精准推送
// 主节点处理请求 const cursor = db.oplog.rs.find({ts: {$gt: 从节点的lastTS}}) .batchSize(100); // 分批发送从节点重放操作(安全模式:单线程顺序执行)
ops.forEach(op => { if(op === 'i') db[op.ns].insert(op.o); if(op === 'u') db[op.ns].update(op.where, op.o); if(op === 'd') db[op.ns].delete(op.o); });
- 保证数据安全的三大机制
- 幂等性设计
- 严格顺序性
- 流量控制(防副本集拖垮主节点):当主节点压力大时,会让从节点暂停拉取oplog(类似主播说:"观众太多,弹幕先停一停!")
- 通过oplog机制,MongoDB实现了:
- 秒级数据同步
- 数据零丢失(除非主节点未持久化)
- 自动断点续传
- 集群负载均衡

